Technical Implementation
Breaking the “Pilot Fallacy”: Scaling AI Agents from Sandbox to Production
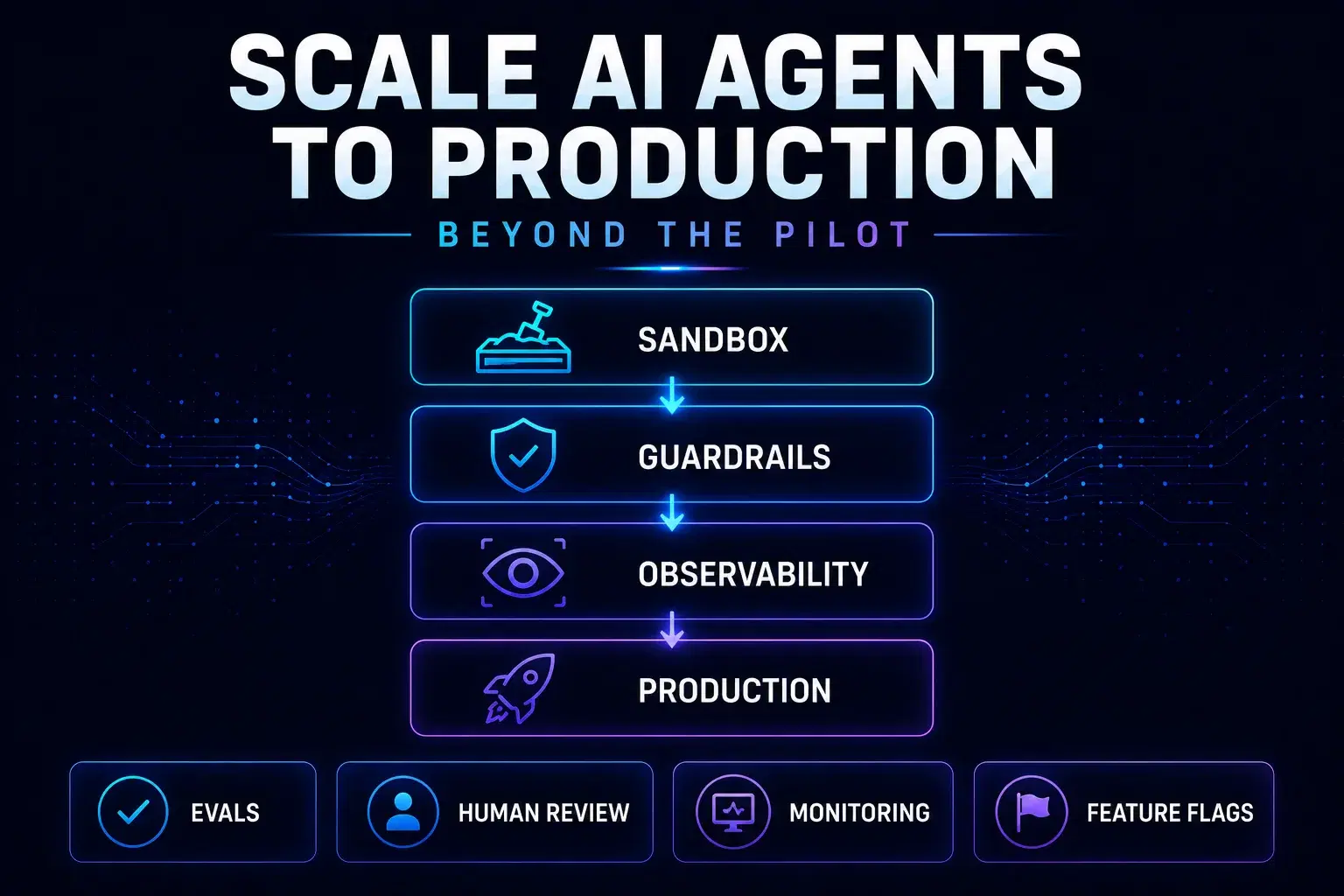
An 80% success rate wins a demo and loses a production rollout. Scaling agents requires the same discipline as any mission-critical software—plus new tooling for nondeterminism and abuse.
Related work
Production builds that connect to this topic—open a case study or jump to our portfolio.



Sandboxes reward happy-path demos. Production punishes every missing guardrail: malformed inputs, ambiguous policies, stale retrieval, adversarial prompts, and integrations that return errors at 2 a.m. The “pilot fallacy” is believing that a successful proof-of-concept automatically transfers to sustained value. Closing the gap requires treating agents as distributed systems with probabilistic components—observable, testable, and owned by an on-call mindset.
What the reliability gap actually is
In deterministic software, identical inputs yield identical outputs. Agents combine models, tools, and retrieval—so outputs vary. Reliability is not “always the same answer”; it is bounded behavior: correct refusals, consistent policy application, safe tool use, and graceful degradation when context is insufficient.
Evaluations: the production prerequisite
- Golden datasets per workflow with expected tool calls and structured outputs.
- Regression suites when prompts, tools, or models change—treat upgrades like schema migrations.
- Online metrics: task success rate, escalation rate, user corrections, latency, and cost per task.
- Safety tests for injection, jailbreaks, and data exfiltration paths relevant to your threat model.
Multi-agent patterns: executor + critic
A common production pattern pairs an executor agent with a verifier or critic: propose an action, validate against policy and facts, then proceed or escalate. This adds latency but reduces catastrophic mistakes in finance, healthcare, and customer-facing workflows where a single wrong tool call is unacceptable.
Observability: traces, not just logs
Standard request logs are insufficient. You need traces across retrieval, model calls, tool invocations, and post-processing—correlated with user/session IDs (respecting privacy). This is how teams answer: why did we refuse? why did we hallucinate? which tool failed?
| Area | Minimum bar |
|---|---|
| Data | Access control on retrieval; PII redaction where required |
| Models | Version pinning; rollback plan; latency/cost budgets |
| Tools | Schemas; timeouts; retries; idempotency keys |
| Security | Injection testing; least-privilege credentials |
| Operations | Runbooks; error budgets; owner on-call |
Rollout strategy that survives scrutiny
- Shadow mode: log proposed actions without executing.
- Canary cohorts: internal users, then a narrow customer segment.
- Feature flags: instant disable without redeploying everything.
- Post-incident reviews: blameless, with concrete test additions.
How we help
Silicon Tech Solutions ships production AI systems with engineering rigor: evaluations, integrations, and operational practices that match your risk level. If you are past the pilot and need scale, we can help you close the reliability gap with evidence—not optimism.
Frequently asked questions
Related articles
Technical Implementation
Democratizing Data: Natural Language Queries for Business Intelligence
Letting everyone ‘ask anything’ without governance creates wrong answers at scale. The best programs pair natural language with metrics definitions, permissions, and validation—not raw database chat.
12 min read · AI Engineering & Architecture
Technical Implementation
Model Context Protocol (MCP) and the Future of Cross-Platform Agentic Workflows
Agents need more than a model—they need governed access to systems of record. MCP-style standards are about composable, auditable connections instead of one-off integration spaghetti.
13 min read · AI Engineering & Architecture
Technical Implementation
The RAG Architecture Guide for Enterprise AI Search
RAG is not “dump documents into a vector DB.” It is information architecture: entities, freshness, permissions, and factual density so models retrieve the right evidence every time.
15 min read · AI Engineering & Architecture
Plan your next build with us
Book a working session to review workflows, integrations, or AI architecture—or send a message and we'll respond within one business day.