Technical Implementation
The RAG Architecture Guide for Enterprise AI Search
RAG is not “dump documents into a vector DB.” It is information architecture: entities, freshness, permissions, and factual density so models retrieve the right evidence every time.
Related work
Production builds that connect to this topic—open a case study or jump to our portfolio.



Retrieval-Augmented Generation (RAG) grounds language models on your documents and data instead of relying solely on parametric knowledge. For enterprise AI search, the hard part is rarely the embedding model—it is data quality, access control, chunk boundaries, and evaluation. This guide frames the architecture decisions teams must get right before tuning prompts.
Define entities before you index
Ambiguous content produces ambiguous retrieval. Make entities explicit: product names, policy IDs, regions, effective dates, and owners. When pages mix multiple topics, split them so each chunk answers one question cleanly—this improves both vector search and citation quality for generative answers.
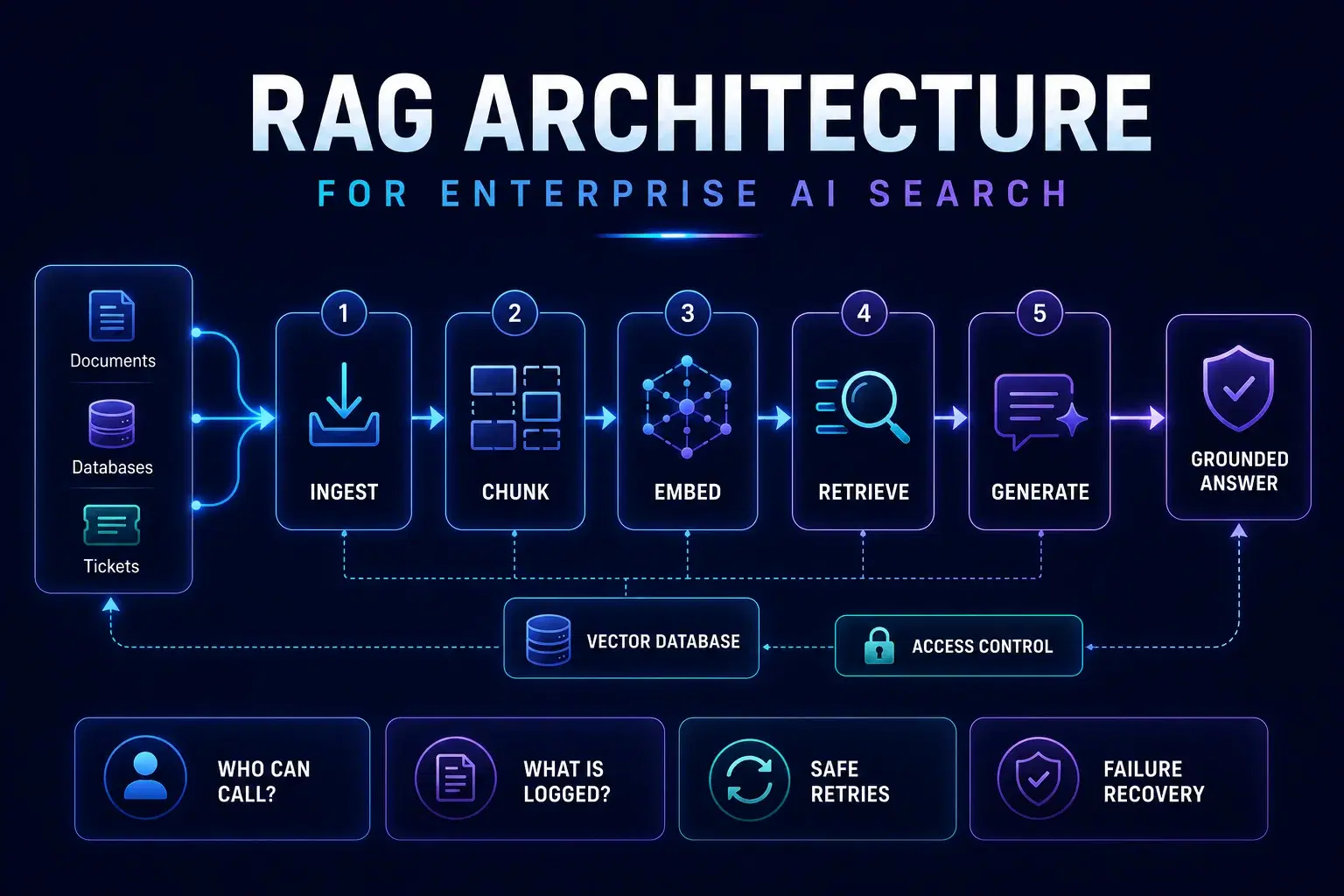
The RAG pipeline: ingest → chunk → embed → retrieve → generate
- Ingest: connect authoritative sources (wikis, tickets, PDFs, databases) with freshness and ACLs.
- Chunk: size and overlap tuned to your content—not generic defaults.
- Embed: choose embedding models consistent across index and query; version them.
- Retrieve: hybrid search (keyword + vector) often beats vector-only for named entities and SKUs.
- Generate: constrain outputs to citations; refuse when evidence is weak.
Vector databases: what they buy you
Managed vector stores (and self-hosted equivalents) provide approximate nearest-neighbor search at scale with metadata filters—critical for tenant isolation and document-level permissions. Treat the index like a derived cache: rebuildable from source systems with clear lineage.
How you know RAG is working
| Metric | What it tells you |
|---|---|
| Context precision | Retrieved chunks are relevant to the question |
| Answer faithfulness | Claims are supported by retrieved text |
| Permission violations | Should be zero in production |
| p95 latency | User experience and cost tradeoffs |
Common failure modes
- Stale content indexed without invalidation.
- Chunks that split tables or procedures mid-step.
- Over-large contexts that dilute signal and increase cost.
- Missing access checks—retrieval must enforce authZ, not only the UI.
How we help
Silicon Tech Solutions builds RAG pipelines, integrations, and evaluation harnesses for production use—not demos. If enterprise AI search is on your roadmap, we can help you architect retrieval that holds up under real queries and permissions.
Frequently asked questions
Related articles
Technical Implementation
Democratizing Data: Natural Language Queries for Business Intelligence
Letting everyone ‘ask anything’ without governance creates wrong answers at scale. The best programs pair natural language with metrics definitions, permissions, and validation—not raw database chat.
12 min read · AI Engineering & Architecture
Technical Implementation
Model Context Protocol (MCP) and the Future of Cross-Platform Agentic Workflows
Agents need more than a model—they need governed access to systems of record. MCP-style standards are about composable, auditable connections instead of one-off integration spaghetti.
13 min read · AI Engineering & Architecture
Technical Implementation
Breaking the “Pilot Fallacy”: Scaling AI Agents from Sandbox to Production
An 80% success rate wins a demo and loses a production rollout. Scaling agents requires the same discipline as any mission-critical software—plus new tooling for nondeterminism and abuse.
14 min read · AI Engineering & Architecture
Plan your next build with us
Book a working session to review workflows, integrations, or AI architecture—or send a message and we'll respond within one business day.